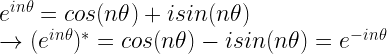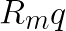(Note: Since this article is imported from my personal Hackmd, some symbols and formatting might not display properly in WordPress. I appreciate your understanding, sorry for any inconvenience.)
RoPE is a method for introducing relative position information into the self-attention mechanism through absolute positional encoding.
In simple terms, the original Transformer architecture uses a sinusoidal function for positional encoding, which is added to the linearly transformed QKV. RoPE, however, calculates a rotary position encoding, which is multiplied with the linearly transformed QK.
In conclusion, given m and n as the positions of the current Q and K, they can be viewed as:
The relative position information between Q and K is explicitly introduced during the inner product, unlike absolute positional encoding, which lets the model learn the positional relationships by itself.
However, the above equation is a mathematical expression to explicitly represent the use of relative positional encoding. In practical applications, we still adhere to the established method of transposing K:
Additionally, in RoPE’s use case, we only apply the rotary position embedding to Q and K, not V.
Assume $q_m$, $k_m$ are two-dimensional vectors at positions m, n. We convert them into complex numbers for inner product computation.
In the vector computation within the complex domain, the inner product of two complex vectors can be represented as the real part of one vector multiplied by the complex conjugate of the other vector.
a, b, c, d are real numbers, and i is the imaginary unit. The conjugate of $k_m$ is $k_m^*=c+di$.
We then take only the real part:
It can be viewed as a computational process like this. However, the derivation isn’t complete yet. If we multiply $q_m$, $k_n$ by $e^{im\theta}$, $e^{in\theta}$ respectively, we introduce absolute position information through n and m.
Through Euler’s formula for complex numbers, we can express $e^{ix}$ as:
Therefore, $e^{im\theta}$ and $e^{in\theta}$ can be interpreted as a ‘rotation’ on the complex plane, possessing periodicity and order.
So, based on the above definitions, we can derive:
Since we have confirmed that the rotational relationship between m-n can be computed through the inner product, for the two-dimensional vector $q_m$ at position m, multiplying it by $e^{im\theta}$ allows the subsequent computation to capture the relative information between $k_n$. We can express this rotation matrix as:
The above is for two-dimensional vectors. If we extend this to even dimensions in d-dimension tasks, we can concatenate rotation matrices, giving the vector q at position m the matrix ${R_m}$:
We expand it as:
However, because $R_m$ is too sparse, in engineering implementations, we can treat it as an equivalent representation:
Note: The symbol ⨂ above represents element-wise multiplication.
Implementation
Based on the derivation results given by SuShen, we can implement it directly in PyTorch. The only thing to note is that in the derivation above, we assume the input position information is at a specified position m. However, in practical computation, we calculate all positions (0…max_len) at once.
class RoPEPositionEmbedding(torch.nn.Module):
def __init__(self, dim: int, max_len: int = 512, base: int = 10000) -> None:
super().__init__()
self.theta = 1 / (base ** (torch.arange(0, dim, 2).float() / dim))
self.theta = self.theta.repeat_interleave(2)
self.position_ids = torch.arange(0, max_len)
def forward(self, x: torch.Tensor):
position_matrix = torch.outer(self.position_ids, self.theta)
cos = torch.cos(position_matrix)
sin = torch.sin(position_matrix)
_x = torch.empty_like(x)
_x[..., 0::2] = -x[..., 1::2]
_x[..., 1::2] = x[..., 0::2]
_x = _x * sin
x = x * cos
out = x + _x
return out
After completing the implementation, I compared it with the RoPE in transformers, and the implementation is clearly different. However, when compared to the open-source project: https://github.com/lucidrains/rotary-embedding-torch, my implementation:
import torch
from rotary_embedding_torch import RotaryEmbedding
# instantiate the positional embedding in your transformer and pass to all your attention layers
rotary_emb = RotaryEmbedding(dim = 32)
# mock queries and keys - dimensions should end with (seq_len, feature dimension), and any number of preceding dimensions (batch, heads, etc)
q = torch.randn(1, 8, 1024, 64) # queries - (batch, heads, seq len, dimension of head)
k = torch.randn(1, 8, 1024, 64) # keys
# apply the rotations to your queries and keys after the heads have been split out, but prior to the dot product and subsequent softmax (attention)
q = rotary_emb.rotate_queries_or_keys(q)
k = rotary_emb.rotate_queries_or_keys(k)
# then do your attention with your queries (q) and keys (k) as usual
produces exactly the same output. It is worth considering as a reference.
As for the difference between RoPE in Mistral / Llama-2 implemented in transformers and the original version, the specific difference lies in:
The original implementation:
But in transformers’ implementation, it can be viewed as:
So, to implement the same version as RoPE in transformers, it needs to be written as:
class HFRoPEPositionEmbedding(torch.nn.Module):
def __init__(self, dim: int, max_len: int = 512, base: int = 10000) -> None:
super().__init__()
self.theta = 1 / (base ** (torch.arange(0, dim, 2).float() / dim))
self.theta = torch.cat([self.theta, self.theta], dim=-1)
self.position_ids = torch.arange(0, max_len)
def forward(self, x: torch.Tensor):
position_matrix = torch.outer(self.position_ids, self.theta)
cos = torch.cos(position_matrix)
sin = torch.sin(position_matrix)
x1 = x[..., : x.shape[-1] // 2]
x2 = x[..., x.shape[-1] // 2 :]
_x = torch.cat([-x2, x1], dim=-1)
x = x * cos
_x = _x * sin
out = x + _x
return out
Although it differs from the original complex rotation, it still attempts to apply the concept of rotation to capture relative positional encoding. These are just my personal insights after reading the source code, and if there are any mistakes, I welcome corrections from experts.


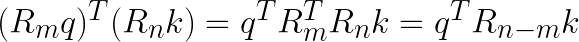

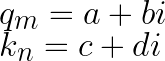
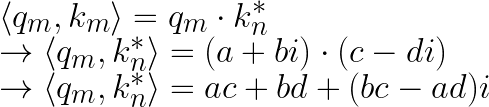
![\left \langle q_m, k_m \right \rangle = Re[q_m, k_n^*] = ac+bd](https://s0.wp.com/latex.php?latex=%5Cleft+%5Clangle+q_m%2C+k_m+%5Cright+%5Crangle+%3D+Re%5Bq_m%2C+k_n%5E%2A%5D+%3D+ac%2Bbd+&bg=ffffff&fg=000&s=4&c=20201002)
![\left \langle q_{m}e^{im\theta}, k_{m}e^{in\theta} \right \rangle = Re[(q_{m}e^{im\theta}), (k_{n}e^{in\theta})^*] = Re[q_{m}k_{n}^{*}e^{i(m-n)\theta}]](https://s0.wp.com/latex.php?latex=%5Cleft+%5Clangle+q_%7Bm%7De%5E%7Bim%5Ctheta%7D%2C+k_%7Bm%7De%5E%7Bin%5Ctheta%7D+%5Cright+%5Crangle+%3D+Re%5B%28q_%7Bm%7De%5E%7Bim%5Ctheta%7D%29%2C+%28k_%7Bn%7De%5E%7Bin%5Ctheta%7D%29%5E%2A%5D+%3D+Re%5Bq_%7Bm%7Dk_%7Bn%7D%5E%7B%2A%7De%5E%7Bi%28m-n%29%5Ctheta%7D%5D+&bg=ffffff&fg=000&s=2&c=20201002)