
Last Updated on 2024-12-03 by Clay
前言
最近在實作論文 Kangaroo: Lossless Self-Speculative Decoding via Double Early Exiting 時,對於其所採用 Cross Entropy Loss 來讓 draft model 和 target model 的機率分佈輸出越像越好這件事,產生了一個疑惑:為什麼不使用 KL Divergence 呢?
通俗來說,我們知道 Cross Entropy 和 KL Divergence 都是用於衡量兩個分佈;Cross Entropy 用來衡量兩個分佈 p 和 q 之間的相似程度、KL Divergence 用來衡量兩個分佈 p 和 q 之間的距離。
其中,p 我們定義為真實分佈,q為預測分佈。一般以深度學習的角度來說,我們希望預測分佈 q 能夠跟真實分佈 p 越像越好。
數學定義
Cross-Entropy(交叉熵)

KL Divergence(KL 散度)


也就是說,我們可以想像 Cross-Entropy 其實比 KL Divergence 多包含一個真實分佈 p 的熵值 
為什麼是完全等價的呢?這是因為本來兩者之間差異的 $H(x)$ ,是目標分佈(真實分佈)的熵,可以寫為:


這樣一來:

此時 KL Divergence 跟 Cross-Entropy 不能說很像,只能說是一模一樣!
Cross-Entropy 和 KL Divergence 的差異
接下來終於要進入正題了:Cross-Entropy 和 KL Divergence 的差異在哪呢?
其實我們剛剛已經提過了,在 hard label 時是等價的,那麼在 soft label 時就不同了。
對於 Cross-Entropy 來說,對於某一個特定類別 x 都會是使用 
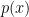
而 KL Divergence 就不同了,每個類別的貢獻都會按照 

舉個實際的案例來看:
import torch
# Define the distributions P and Q
P = torch.tensor([0.98, 0.01, 0.01]) # Target distribution
Q = torch.tensor([0.979, 0.02, 0.001]) # Model predicted distribution
# Compute the contributions of each class to Cross Entropy
cross_entropy_contributions = -P * torch.log(Q)
total_cross_entropy = torch.sum(cross_entropy_contributions)
cross_entropy_ratios = cross_entropy_contributions / total_cross_entropy
# Compute the contributions of each class to KL Divergence
kl_divergence_contributions = P * (torch.log(P) - torch.log(Q))
total_kl_divergence = torch.sum(kl_divergence_contributions)
# Calculate the absolute proportion of each class's contribution to KL Divergence
kl_divergence_absolute_ratios = torch.abs(kl_divergence_contributions) / torch.sum(torch.abs(kl_divergence_contributions))
# Print the results for Cross Entropy contributions
print("Cross Entropy Contributions:")
for i, contrib in enumerate(cross_entropy_contributions):
print(f"Class {i}: {contrib.item()} (Proportion: {cross_entropy_ratios[i].item():.2%})")
# Print the results for KL Divergence contributions
print("\nKL Divergence Contributions:")
for i, contrib in enumerate(kl_divergence_contributions):
print(f"Class {i}: {contrib.item()} (Absolute Proportion: {kl_divergence_absolute_ratios[i].item():.2%})")
Output:
Cross Entropy Contributions: Class 0: 0.020799191668629646 (Proportion: 16.12%) Class 1: 0.039120230823755264 (Proportion: 30.33%) Class 2: 0.06907755136489868 (Proportion: 53.55%) KL Divergence Contributions: Class 0: 0.0010005577933043242 (Absolute Proportion: 3.23%) Class 1: -0.006931471638381481 (Absolute Proportion: 22.39%) Class 2: 0.02302584983408451 (Absolute Proportion: 74.38%)
我們可以看到,在 Cross-Entropy 中最關心的還是大機率的類別,也就是 class 0,在我們的預測分佈跟真實分佈只差 0.001 時,Cross-Entropy 的 loss 就貢獻了 16.12%,相比之下 KL Divergence 只貢獻了 3.23%;不過反來說,在 class 2 的情況我們的預測分佈與真實分佈差了一個數量級,但是 在 KL Divergence 貢獻的 loss 就硬是比 Cross Entropy 多了 20%。
這確實說明了 KL Divergence 其實看重整體分佈的形狀(每一個類別),而 Cross Entropy 則更關注真實分佈中容易出現的類別。
延伸討論
不過在我們拿 Cross Entropy 和 KL Divergence 來當作損失函數(loss function)而非拿來衡量資訊系統的差異時,可以視為等價的。
這是因為 KL Divergence 和 Cross Entropy 只差一個目標分佈的熵 $H(p)$,並且在目標分佈為 ground truth 的情況下就是一個妥妥的常數項。


所以在微分後,使用 KL Divergence 和 Cross Entropy 所得到的梯度應該是相同的。
相關的討論也可以參考 https://ai.stackexchange.com/questions/3065/why-has-the-cross-entropy-become-the-classification-standard-loss-function-and-n 這個討論。
總結
現在的話,我似乎能理解我正在實作、實驗的那篇論文為什麼是採用 Cross Entropy 而非 KL Divergence 了。我很直覺地希望 draft model 和 target model 之間的輸出機率分佈應該相似且一致,但是搞不好原作者團隊其實更看重高機率的類別(因為解碼時需要讓 draft model 產生出來的 token 被 target model 所接受)。
我決定再多做一點實驗來確認,因為在我的初步的實驗結果中,採用 KL Divergence 的接受率比 Cross-Entropy 高兩個數量級 —— 當然,也有一種可能是因為我採樣的溫度太高了,導致 KL Divergence 效果就是好。