

LSTM (Long Short-Term Memory), is a type of Recurrent Neural Network (RNN). The paper about LSTM was published in 1997, which is a very important and easy-to-use model layer in natural language processing.
Since I often use LSTM to handle some tasks, I have been thinking about organizing a note. In this way, if I encounter LSTM-related problems in the future, I can read this note, saving time to browse on the Internet.
For my own convenience, this note will be divided into two parts.
The first part is to record the principle of LSTM, and the second half is specifically to record the format of LSTM used in PyTorch.
The Principle Of LSTM
Since this article is an article I used to record the studying process, some pictures and explanations of the principles are based on other people’s articles. The following links to the reference pages will be attached to the “References” section at the bottom. The sample pictures are infringing, please tell me for removing.
LSTM can be regarded as a complex version of RNN.
There will be parameter transfer between neurons in different time series.
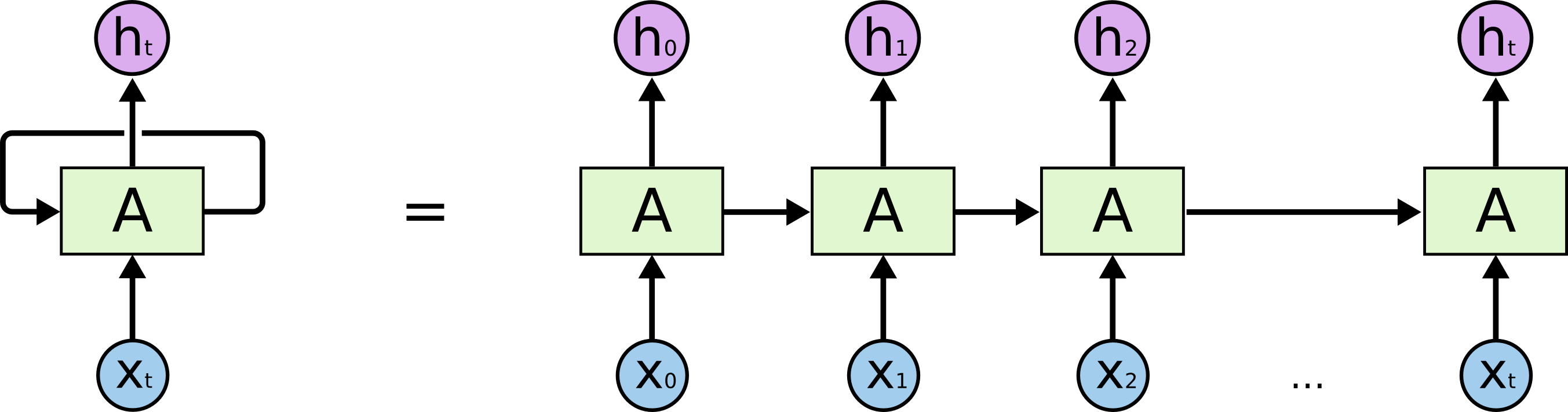
The following is a diagram of the architecture of an RNN. It can be seen that in addition to the h value that forward propagate, neurons transmit information to each other in time sequence
LSTM 可以視為 RNN 的複雜版本,基本上最重要的是就是在不同時序的神經元間會有參數傳遞。以下是個 RNN 的架構圖,可以看到除了向前傳播的 h 值以外,神經元彼此之間按照時序傳遞資訊。
However, the architecture of a single neuron in LSTM is significantly more complicated:


Let’s take a look at the neuron data processing process.
It will be clearer to think slowly according to the formula.

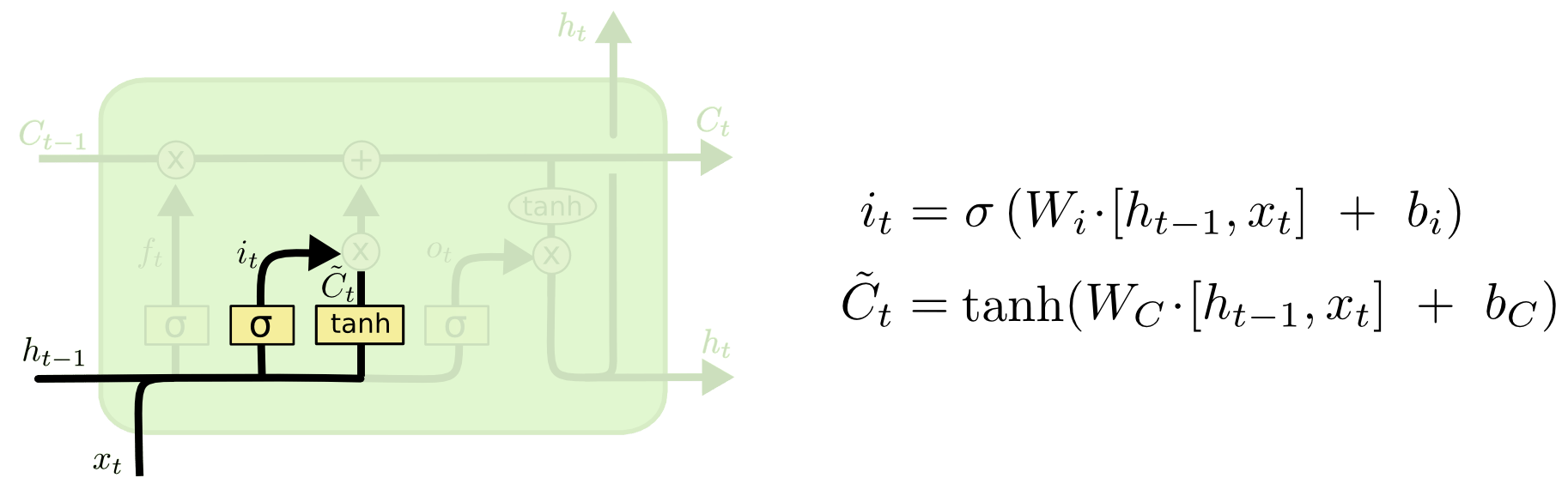

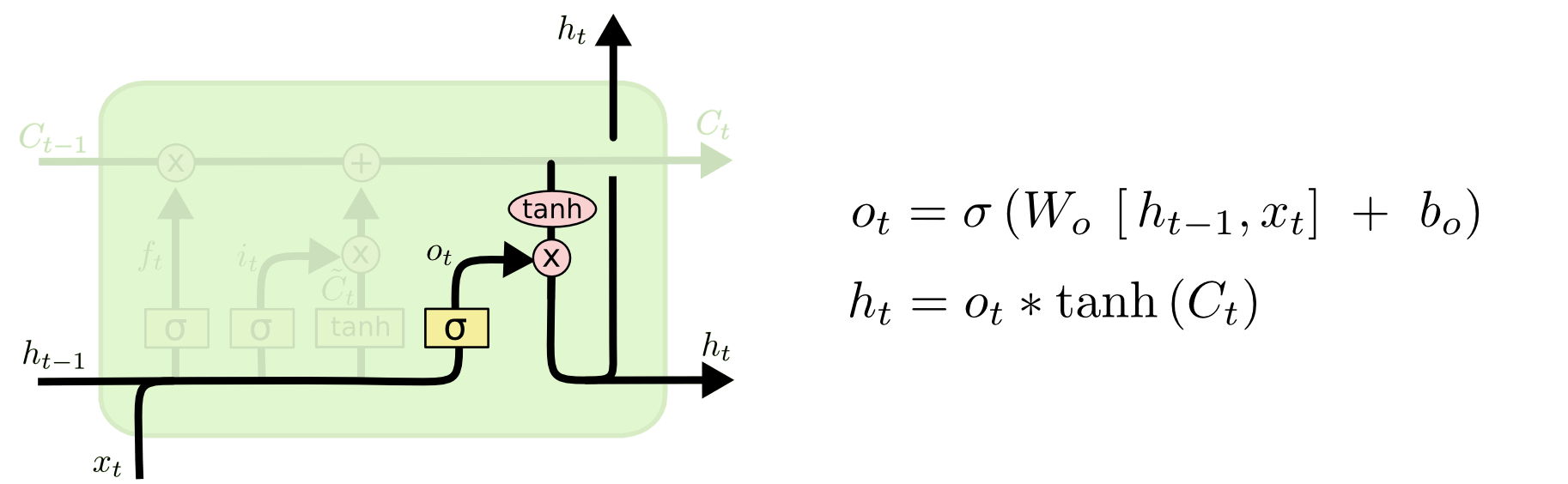
How To Use LSTM In PyTorch
LSTM parameters:
- input_size: Enter the number of features in
x - hidden_size: The number of features in the hidden layer
h - num_layers: The number of loop layers of LSTM (Default=1)
- bias: If it is False, the bias is initialized to 0 (Default=True)
- batch_first: If True, the input dimension is (
batch_size,seq_len,feature) - dropout: If it is not 0, dropout will follow after each layer of LSTM (Default=0)
- bidirectional: If True, it is a bi-directional LSTM (Default=False)
I want to record some changes in the data in LSTM.
First, we assume that the dimensions of the input are (batch_size, seq_len, input_size). Of course, this is the case of batch_first=True.
The model defined in PyTorch is as follows:
# coding: utf-8 import torch.nn as nn # LSTM class LSTM(nn.Module): def __init__(self, input_size, hidden_size, num_layers, bidirectional): super(LSTM, self).__init__() self.lstm = nn.LSTM( input_size=input_size, hidden_size=hidden_size, num_layers=num_layers, bidirectional=bidirectional, ) self.fc = nn.Linear(hidden_size, 1) self.sigmoid = nn.Sigmoid() def forward(self, inputs): out, (h_n, c_n) = self.lstm(inputs, None) outputs = self.fc(h_n.squeeze(0)) return self.sigmoid(outputs)
As we can see, this is an LSTM classifier. There are three outputs: out, h_n and c_n. Let’s take a look separately below.
out (batch_first=True)
out: (batch_size, seq_len, hudden_size * num_directions)
out is a three-dimensional tensor.
The first dimension is batch size.
The second dimension is the sequence length.
The third dimension is “hidden layer size * num_directions“.
The hidden layer size is the size set by hidden_size, and num_directions is 2 for bidirectional LSTM and 1 for unidirectional.
h_n
h_n: (num_layers * num_directions, batch_size, hidden_size)
num_layers means that there are several hidden layers in LSTM. except for the explanation of out above.
c_n
c_n: (num_layers * num_directions, batch_size, hidden_size)
The structure of c_n and h_n is similar, the only difference is that h_n is the output of h and c_n is the output of c.
You can refer to the structure diagram above.
Output of Bi-LSTM
Bi-LSTM is different.
Since the final output is bi-direction, we will get the forward-sequential output and a reverse-sequenced output.
At this time, if they are directly combined for classification, the effect is usually not very good.
What we have to do is reverse the output of the reverse sequence and merge it with the output of the sequence.
By the way, setting Bidirectional=True is a little problematic (in PyTorch 1.2), The biggest problem is that the output can not be fixed with a fixed seed.
This is dangerous in experimental models, because you cannot repeat the experiments you have done.
References
- https://colah.github.io/posts/2015-08-Understanding-LSTMs/
- https://adventuresinmachinelearning.com/keras-lstm-tutorial/
- https://medium.com/mlreview/understanding-lstm-and-its-diagrams-37e2f46f1714
- https://pytorch.org/tutorials/beginner/nlp/sequence_models_tutorial.html
- https://pytorch.org/tutorials/intermediate/char_rnn_classification_tutorial.html