

Last Updated on 2025-07-01 by Clay
Recently, I’ve still been diving into inference acceleration techniques, but work has kept me too busy to publish any updates. Today, I’m introducing a classic multi-head decoding architecture called Medusa.
Medusa, inspired by the mythological Greek figure also known as the “snake-haired woman,” has each decoding head metaphorically representing a snake. The architecture mirrors this imagery with multiple decoding heads.
Most large language models today use auto-regressive decoding, where each output token depends on the one generated before it—creating a computational bottleneck.
Among existing methods, Speculative Decoding is an effective way to accelerate inference. However, it requires maintaining a separate draft model, adding complexity in both deployment and management. (You can refer to my previous notes: [Paper Review] Fast Inference from Transformers via Speculative Decoding and [Paper Review] Draft & Verify: Lossless Large Language Model Acceleration via Self-Speculative Decoding)
The Medusa architecture, meanwhile, not only uses different decoding heads to predict tokens at different time steps, but also introduces a tree-based attention mechanism to validate multiple candidate outputs in parallel. Unlike most Speculative Decoding methods, Medusa does not guarantee output distribution alignment with the original LLM. Thus, performance must be empirically validated.
The study proposes two training strategies:
- Medusa-1: Fine-tunes only the Medusa heads on a frozen base model. It preserves output quality and provides up to 2.2× acceleration.
- Medusa-2: Jointly fine-tunes with the base model, improving prediction accuracy of the Medusa heads and achieving 2.3× to 2.8× speedup. However, it requires more training.
Medusa Architecture
The two most crucial components in Medusa are the multiple decoding heads and the tree-based attention mechanism.
Multiple Decoding Heads
The decoding head structure is shown below:

In practice, retraining the entire decoding layer may introduce too many parameters (head_num * last_hidden_size * vocab_size). A simpler approach is to share the final decoding layer and declare the Medusa heads as multiple linear layers. This reduces the parameter count to head_num * last_hidden_size * last_hidden_size * layer_num, which is much smaller since vocab_size is typically much larger than last_hidden_size.
Tree-based Attention Mechanism
Tree-based attention is used to validate multiple decoding candidates. In the image below, the checkmarks indicate the parts the model can see. The rest are masked out via attention.
There are a total of 6 candidate paths shown below:
- Head 1: [“It”, “I”]
- Head 2: [“is”, “‘”, “the”]
2 * 3 = 6, so we can combine into:
- It is
- It’
- It the
- I is
- I’
- I the

Instead of using Reject Sampling like in Speculative Decoding, Medusa adopts the classic Typical Acceptance Scheme.
The core idea is to not require the predicted token distribution to match the original model exactly. Instead, it accepts the most “typical” sequence. Rather than relying on a hard threshold, Medusa introduces entropy to dynamically adjust the threshold: allowing more token diversity when entropy is high and being stricter with high-probability tokens when entropy is low.
This might still sound vague — let’s look at the formula.
Assume we define the sequence













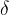
If multiple candidate sequences are accepted, the longest one is selected to maximize acceleration.
Training Strategy 1: Medusa-1 Frozen Backbone
The most classic setup trains only the added Medusa heads while freezing the original base model.
Training data can come from any dialogue dataset, but a better method is to let the base model generate responses to prompts so that Medusa heads can learn from the base model’s true output distribution — ensuring high acceptance rates.
The loss function can simply be cross-entropy. We down-weight losses from heads predicting tokens further in the future — allowing those heads to relax their learning pressure.


Here,


Training Strategy 2: Medusa-2 Joint Training
Combine Loss
To preserve the next-token prediction ability of the original model, we include the original cross-entropy loss with the Medusa loss.


The full loss becomes:


Different Learning Rates
Although not explicitly detailed, the paper suggests using different optimizers or learning rates for the pretrained base model and the newly initialized Medusa heads.
Heads Warmup
It is recommended to warm up by training only the Medusa heads (as in Medusa-1), then proceed to full joint training in Medusa-2 — letting both the base model and heads update together.
Self-Distillation
Training the Medusa decoding heads requires data that reflects the base model’s output distribution. However, this is challenging when the original training data is unavailable or the model has been fine-tuned via methods like RLHF, which shift its distribution.
This is where “Self-Distillation” comes in — generating a suitable dataset using the model itself.
The idea is intuitive: select a seed dataset from public sources, use its prompts as inputs to the base model, and collect the model’s responses. This newly generated dataset is then used to train the Medusa heads.
This works well for Medusa-1 (frozen base model), but not for Medusa-2 (joint training). Using hard labels from self-distilled data can harm performance when fine-tuning the base model.
Here’s my personal interpretation: Initially, I thought that training on data generated by the model itself would preserve performance. But then I realized that the model’s output usually reflects nuanced distributions, with different outputs possible under different sampling conditions. Training on hard labels from its own outputs might overfit the model to specific preferences — eventually degrading its flexibility and performance.
To address this, Medusa-2’s loss function uses the original model’s probability distribution instead of hard labels — effectively performing Knowledge Distillation (KD):


Experimental Results
Finally, here are the results from the Medusa research team.
On both Vicuna 7B and 13B, they achieved a 2.18x–2.33x speedup with Medusa-1 and 2.83x with Medusa-2.

While the speedups are impressive, I still feel a bit uneasy about the mismatch between output distribution and the original model. Hopefully, the upcoming Eagle paper will explain how it manages to use tree-based attention while retaining the same output distribution as the base model.