
Last Updated on 2024-03-08 by Clay
LayerNorm 的工作原理如下:
- 計算均值(mean)和方差(variance)
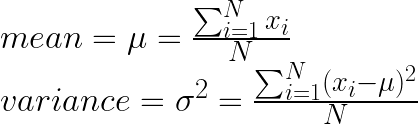
- 使用均值與方差進行標準化
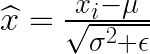
ϵ 是一個很小的數字,用來避免分母為 0。
- 線性變換
最後,會使用可學習的參數:比例參數 γ 和偏移參數 β(這兩個參數通過訓練得來,初始化 γ = 1 而 β = 0)來對每個輸入元素進行線性變換。
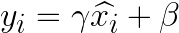
這種作法是希望模型在一開始不對標準化後的輸出進行任何調整,逐步讓模型自己學習找到最適合的調整參數。
PyTorch 的簡易實現版本可以看成:
import torch
class MyLayerNorm(torch.nn.Module):
def __init__(self, normalized_shape, eps: float = 1e-5) -> None:
super().__init__()
self.eps = eps
self.gamma = torch.nn.Parameter(torch.ones(normalized_shape))
self.beta = torch.nn.Parameter(torch.zeros(normalized_shape))
def forward(self, x: torch.Tensor) -> torch.Tensor:
mean = x.mean(dim=(-1,), keepdim=True)
std = x.std(dim=(-1,), keepdim=True, unbiased=False)
x_normalized = (x - mean) / (std + self.eps)
return self.gamma * x_normalized + self.beta
# Inputs
batch_size = 4
dim = 20
x = torch.rand(batch_size, dim)
# My LayerNorm
my_layer_norm = MyLayerNorm(normalized_shape=20)
x_normalized = my_layer_norm(x)
# Official LayerNorm
official_layer_norm = torch.nn.LayerNorm(dim)
x_normalized_official = official_layer_norm(x)
print("Diff:", x_normalized - x_normalized_official)
print("Max:", torch.max(x_normalized - x_normalized_official))
Output:
Diff: tensor([[-4.6015e-05, 7.2122e-06, 1.6093e-05, -2.7657e-05, 2.4617e-05,
5.2810e-05, -2.3901e-05, -3.0756e-05, 4.5896e-06, -3.6478e-05,
4.6492e-05, 5.4479e-05, 9.0301e-06, -7.4059e-06, -2.9624e-05,
-3.9577e-05, -3.8147e-05, 1.8299e-05, 2.9027e-05, 1.1176e-05],
[ 1.2219e-05, -1.1958e-06, 1.3947e-05, -1.8477e-05, 3.0756e-05,
-3.0279e-05, -3.4571e-05, -3.5524e-05, 7.5400e-06, 2.5868e-05,
-3.3379e-05, 2.2292e-05, 2.7537e-05, -9.3132e-07, -1.7941e-05,
2.4915e-05, -1.5795e-05, -9.8646e-06, 1.9595e-06, 3.0756e-05],
[ 2.5034e-05, -5.2810e-05, 2.6703e-05, 4.8757e-05, 2.6405e-05,
-8.8215e-06, 2.7299e-05, -1.7226e-05, 1.4827e-06, 2.6643e-05,
9.3132e-09, -5.6386e-05, 2.2948e-05, -1.4678e-06, 9.4771e-06,
-3.9697e-05, -3.8743e-05, 3.2425e-05, -1.5974e-05, -2.0623e-05],
[-5.6624e-05, -1.9819e-05, 5.9962e-05, 3.7998e-06, 7.2598e-05,
-7.7128e-05, 1.0788e-05, 4.2319e-05, 2.0355e-05, 1.6630e-05,
7.0691e-05, -3.1710e-05, -5.1022e-05, -4.5538e-05, -1.3143e-05,
2.3484e-05, -1.4067e-05, -1.2577e-05, -3.9399e-05, 3.8266e-05]],
grad_fn=<SubBackward0>)
Max: tensor(7.2598e-05, grad_fn=<MaxBackward1>)
以上在計算 std 時採用了標準差(Standard Deviation)而非方差(Variance)使其跟原始實現更接近。標準差定義為方差之平方根。