
Last Updated on 2024-03-18 by Clay
介紹
(備註:由於本篇文章自我個人 Hackmd 導入,所以有些符號跟 WordPress 顯示不對位,還請閱讀者多多包涵,Sorry~)
RoPE 是一種通過絕對位置編碼的方式,引入相對位置的資訊給自注意力機制(Self-Attention Mechanism)的位置嵌入。

簡單來說,原始 Transformer 架構所使用的是 Sinusoidal 函數是作為位置編碼,與線性變換後的 QKV 相加;而 RoPE 則是計算出旋轉位置編碼,與線性變換後的 QK 相乘。
以結論來說,給定 m, n 分別為當前計算的 Q, K 之位置,則可以將其視為:
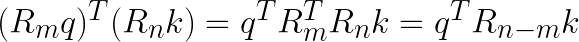
其 Q 和 K 之間相對的位置資訊會在做內積時明確被引入,跟讓模型自行學習位置關係的絕對位置編碼不同。
不過上式是為了建構一個顯式地表示相對位置編碼的用處的數學式,實際應用場景我們仍然是遵守既定的將 K 轉置的方法:

並且,在 RoPE 的使用場景中,我們只會將 Q 和 K 乘上旋轉位置嵌入,而 V 則沒有進行這一處理。
推導
以下的推導來自於原作者苏神的網站,主要參考《让研究人员绞尽脑汁的Transformer位置编码》、《Transformer升级之路:2、博采众长的旋转式位置编码》。
假設 $q_m$, $k_m$ 是位置於 m, n 的二維向量,我們將其轉為複數進行內積計算。
在複數域的向量計算中,兩複數向量的內積可以表示成一個向量和另外一個向量的共軛(complex conjugate)相乘的實部。
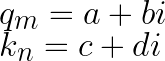
a, b, c, d 為實數, i 為虛數單位。 $k_m$ 的共軛 $k_m^*=c+di$。
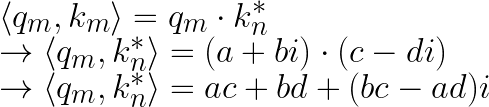
然後我們只取實部:
![\left \langle q_m, k_m \right \rangle = Re[q_m, k_n^*] = ac+bd](https://s0.wp.com/latex.php?latex=%5Cleft+%5Clangle+q_m%2C+k_m+%5Cright+%5Crangle+%3D+Re%5Bq_m%2C+k_n%5E%2A%5D+%3D+ac%2Bbd+&bg=ffffff&fg=000&s=4&c=20201002)
可以視為這樣的一個計算過程。然而,推導還沒有結束。
如果我們把 $q_m$, $k_n$ 分別乘上 $e^{im\theta}$, $e^{in\theta}$,便可視為透過 n, m 加入了絕對位置的資訊。
![\left \langle q_{m}e^{im\theta}, k_{m}e^{in\theta} \right \rangle = Re[(q_{m}e^{im\theta}), (k_{n}e^{in\theta})^*] = Re[q_{m}k_{n}^{*}e^{i(m-n)\theta}]](https://s0.wp.com/latex.php?latex=%5Cleft+%5Clangle+q_%7Bm%7De%5E%7Bim%5Ctheta%7D%2C+k_%7Bm%7De%5E%7Bin%5Ctheta%7D+%5Cright+%5Crangle+%3D+Re%5B%28q_%7Bm%7De%5E%7Bim%5Ctheta%7D%29%2C+%28k_%7Bn%7De%5E%7Bin%5Ctheta%7D%29%5E%2A%5D+%3D+Re%5Bq_%7Bm%7Dk_%7Bn%7D%5E%7B%2A%7De%5E%7Bi%28m-n%29%5Ctheta%7D%5D+&bg=ffffff&fg=000&s=2&c=20201002)
透過複數的 Euler 公式,我們可以把 $e^{ix}$ 表示成:

所以在 $e^{im\theta}$ 和 $e^{in\theta}$ 的理解上,可以視為其表示在複數平面上的『旋轉』,擁有週期性與順序。
引用自 https://en.wikipedia.org/wiki/Euler%27s_formul

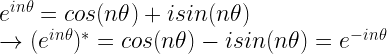
所以根據以上定義,我們可以推導出:

既然我們確認了可以透過內積計算得到 m-n 的旋轉關係,即對於位置 m 的 $q_m$ 二維向量來說,乘上 $e^{im\theta}$ 便可以藉由後續計算得到與 $k_n$ 之間的相對資訊,我們可以將其旋轉矩陣的形式表達成:

以上是在二維向量的情況。如果是在任務偶數維度 d 維的情況下,我們可以將旋轉矩陣拼接成,給定位置為 m 的向量 q 乘上矩陣 ${R_m}$:
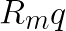
將其展開為:

然而由於 $R_m$ 過於稀疏,所以在工程實現上,可以將其視為另一等價表示:

註:以上 ⨂ 符號為對位相乘。
實作
按照以上苏神給出的推導結果,我們可以直接透過 PyTorch 進行實作。
唯一需要注意的是,在上方推導中,我們是假設輸入的位置資訊為一指定位置 m。但在實際計算中,我們是將 (0…max_len) 的全數位置一同進行計算。
class RoPEPositionEmbedding(torch.nn.Module):
def __init__(self, dim: int, max_len: int = 512, base: int = 10000) -> None:
super().__init__()
self.theta = 1 / (base ** (torch.arange(0, dim, 2).float() / dim))
self.theta = self.theta.repeat_interleave(2)
self.position_ids = torch.arange(0, max_len)
def forward(self, x: torch.Tensor):
position_matrix = torch.outer(self.position_ids, self.theta)
cos = torch.cos(position_matrix)
sin = torch.sin(position_matrix)
_x = torch.empty_like(x)
_x[..., 0::2] = -x[..., 1::2]
_x[..., 1::2] = x[..., 0::2]
_x = _x * sin
x = x * cos
out = x + _x
return out
實作完成後,我有與 transformers 中的 RoPE 做過比較,顯然與那邊實現的方式不同。而在與開源專案:https://github.com/lucidrains/rotary-embedding-torch 的比較上,我的實現與其:
import torch
from rotary_embedding_torch import RotaryEmbedding
# instantiate the positional embedding in your transformer and pass to all your attention layers
rotary_emb = RotaryEmbedding(dim = 32)
# mock queries and keys - dimensions should end with (seq_len, feature dimension), and any number of preceding dimensions (batch, heads, etc)
q = torch.randn(1, 8, 1024, 64) # queries - (batch, heads, seq len, dimension of head)
k = torch.randn(1, 8, 1024, 64) # keys
# apply the rotations to your queries and keys after the heads have been split out, but prior to the dot product and subsequent softmax (attention)
q = rotary_emb.rotate_queries_or_keys(q)
k = rotary_emb.rotate_queries_or_keys(k)
# then do your attention with your queries (q) and keys (k) as usual
的輸出結果一模一樣。應可斟酌參考。
至於 transformers 中 Mistral / Llama-2 的 RoPE 實現跟原始版本哪裡不同,具體來說差異體現在:
原本的實現:

但在 transformers 的實現中,卻可以看成:

所以若是要實現與 transformers 中的 RoPE 同樣的版本,則需要寫成:
class HFRoPEPositionEmbedding(torch.nn.Module):
def __init__(self, dim: int, max_len: int = 512, base: int = 10000) -> None:
super().__init__()
self.theta = 1 / (base ** (torch.arange(0, dim, 2).float() / dim))
self.theta = torch.cat([self.theta, self.theta], dim=-1)
self.position_ids = torch.arange(0, max_len)
def forward(self, x: torch.Tensor):
position_matrix = torch.outer(self.position_ids, self.theta)
cos = torch.cos(position_matrix)
sin = torch.sin(position_matrix)
x1 = x[..., : x.shape[-1] // 2]
x2 = x[..., x.shape[-1] // 2 :]
_x = torch.cat([-x2, x1], dim=-1)
x = x * cos
_x = _x * sin
out = x + _x
return out
雖然與原始的複數旋轉不同,但仍然是一種試圖應用旋轉的概念捕捉相對位置編碼。以上是一些個人看原始碼後的淺見,若有誤還請各方大神不吝指出。
References
- RoFormer: Enhanced Transformer with Rotary Position Embedding
- 《让研究人员绞尽脑汁的Transformer位置编码》
- 《Transformer升级之路:2、博采众长的旋转式位置编码》。