
Last Updated on 2024-08-18 by Clay
高斯誤差線性單元(Gaussian Error Linear Unit, GELU)是一種機器學習中會使用到的激活函數。跟經典的 ReLU(Rectified Linear Unit)雖然相像卻有些地方不盡相同。

ReLU 是分段的線性函數,在輸入小於 0 時等於 0,輸入大於 0 時等於輸入本身。
ReLU(x) = max(0, x)
GELU 由 Dan Hendrycks 和 Kevin Gimpel 在 2016 年提出,結合神經元的輸入以及輸入的標準高斯累積分佈函數,所組成的非線性激活函數。
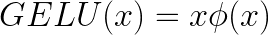
其中,Φ(x) 是其輸入值得標準常態累積分佈函數(Cummuative Distribution Function, CDF) ,可以表示為:
![\phi(x)=\frac{1}{2}[1+erf(\frac{x}{\sqrt{2}})]](https://s0.wp.com/latex.php?latex=%5Cphi%28x%29%3D%5Cfrac%7B1%7D%7B2%7D%5B1%2Berf%28%5Cfrac%7Bx%7D%7B%5Csqrt%7B2%7D%7D%29%5D+&bg=ffffff&fg=000&s=4&c=20201002)
erf() 是一種誤差函數,其定義為:

在 PyTorch 中,我們可以簡單地調用 torch.erf() 來觀察這個函數的表現:
import torch
x = torch.tensor([-2.0, -1.5, -1.0, -0.5, 0, 0.5, 1.0, 1.5, 2.0])
print(torch.erf(y))
# Out: tensor([-0.9953, -0.9661, -0.8427, -0.5205, 0.0000, 0.5205, 0.8427, 0.9661, 0.9953])
當輸入負數時,誤差函數的值同樣為負數,隨著輸入越小,誤差函數的值越小(但可以觀察 e^(-t^2) 可以發現 t 越遠離 0 會導致加起來的積分面積成長率越來越低),但不會小於 -1。
當輸入為 0 時,其輸出同樣為 0,因為積分從 0 到 0。
當輸入為正數時,誤差函數值為正數,同樣隨著輸入越大,誤差函數的值越大,但不會超過 1。
在使用 PyTorch 實現時,GELU 其實還可以有多種不同的近似實作,比如:
![0.5x(1+tanh[\sqrt{\frac{2}{\pi}}(x+0.044715x^{3})])](https://s0.wp.com/latex.php?latex=0.5x%281%2Btanh%5B%5Csqrt%7B%5Cfrac%7B2%7D%7B%5Cpi%7D%7D%28x%2B0.044715x%5E%7B3%7D%29%5D%29+&bg=ffffff&fg=000&s=4&c=20201002)
或者是
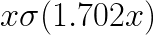
我翻了一下 PyTorch 官方文件跟直接進入 GELU() 實作去看,顯然是有原版的實現已經 Tanh 的近似實現。截止至目前(2024/03/07),Sigmoid 實現還沒有進入 PyTorch,但已經有人在詢問了。
import math
import matplotlib.pyplot as plt
import torch
def GELU(x: torch.Tensor) -> torch.Tensor:
return x * (1 + torch.erf(x / math.sqrt(2))) / 2
def GELU_tanh(x: torch.Tensor) -> torch.Tensor:
return 0.5 * x * (1 + torch.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * pow(x, 3))))
def GELU_sigmoid(x: torch.Tensor) -> torch.Tensor:
return x * torch.sigmoid(1.702 * x)
x = torch.arange(-6, 6, 0.001)
y1 = torch.nn.functional.gelu(x, approximate="tanh")
y2 = torch.tensor(list(map(GELU, x)))
y3 = torch.tensor(list(map(GELU_tanh, x)))
y4 = torch.tensor(list(map(GELU_sigmoid, x)))
plt.plot(x, y1, label="Torch GELU")
plt.plot(x, y2, label="My GELU")
plt.plot(x, y3, label="My GELU_tanh")
plt.plot(x, y4, label="My GELU_sigmoid")
plt.title("GELU")
plt.xlabel("x")
plt.ylabel("y")
plt.legend(loc="upper right")
plt.show()
Output:

print("Original:", max(y1 - y2))
print("Tanh:", max(y1 - y3))
print("Sigmoid:", max(y1 - y4))
Output:
Original: tensor(0.0005) Tanh: tensor(2.3842e-07) Sigmoid: tensor(0.0207)
假設我們在參數中選擇 tanh: torch.nn.functional.gelu(x, approximate="tanh") ,就會自動切換成 Tanh 近似。
但有意思的是一旦把範圍縮小到 -1 到 1 之間,sigmoid 近似就會趨近為 0,感覺是有添加進 PyTorch 原生實現的價值的才是。
總結,GELU 的價值之一在於它在負數域同樣引入了資訊,而非如 ReLU 一般直接設置為 0;另外,GELU 在整個輸入域中都是可微的,不像 ReLU 在零點處不可微分 —— 這種平滑性可以幫助梯度下降更有效地優化。
以實際面來說,GELU 在 BERT 等 Transformer 架構中被廣泛使用,並展示出良好的性能,可以說是久經考驗。