

Last Updated on 2024-08-17 by Clay
Introduction to RMSNorm
RMSNorm is an improvement over LayerNorm, often used in the Transformer self-attention mechanism. It aims to mitigate the issues of vanishing and exploding gradients, helping the model converge faster and improve performance.
In the original LayerNorm, the input elements are first normalized by calculating the mean and variance. Some implementations replace variance with the standard deviation.
Given a layer’s output x = [x_1, x_2, …, x_n], where n is the number of neurons or the feature dimension in the layer.


We can obtain the normalized







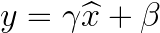
However, in RMSNorm, instead of using the mean and variance, each element is squared, averaged, and then the square root is taken to calculate the norm, a process similar to computing the Root Mean Square (RMS) of a set of data.