

Last Updated on 2024-08-18 by Clay
RMSNorm 介紹
RMSNorm 是對於 LayerNorm 的一種改進,經常用於 Transformer 自注意力機制,旨在減輕梯度消失和梯度爆炸的問題,從而幫助模型更快收斂並提高性能。
原本的 LayerNorm 中,首先會對於輸入元素進行正規化/歸一化,所以首先求出均值(mean)及方差(variance),有的實現則是使用標準差(stdandard deviatino)取代方差。
給定一層輸出 x = [x_1, x_2, …, x_n],其中 n 為該層神經元的數量或特徵維度。

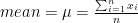
我們可以通過計算均值和方差取得正規化的 $\widehat{x}$ ,然後使用比例參數 $\gamma$ 和偏移參數 $\beta$ 來對每個元素進行線性變換。

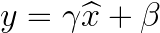
但在 RMSNorm 中,是對每一層的元素進行平方、求平均、再取平方根來計算範數(norm),此過程類似於計算一組資料的均方根(Root Mean Square, RMS)。


之後做正規化後,同樣使用一對可學習的參數 $g$ 和 $b$ 來進行線性變換:

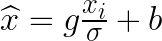
實作
使用 PyTorch 的實作如下:
class RMSNorm(torch.nn.Module):
def __init__(self, normalized_shape, eps: float = 1e-8, use_bias: bool = False) -> None:
super().__init__()
self.eps = eps
self.use_bias = use_bias
self.gamma = torch.nn.Parameter(torch.ones(normalized_shape))
if use_bias:
self.bias = torch.nn.Parameter(torch.zeros(normalized_shape))
self.register_parameter("bias", self.bias)
else:
self.register_parameter("bias", None)
def forward(self, x: torch.Tensor) -> torch.Tensor:
rms_x = x / (torch.sqrt(torch.mean(x ** 2, dim=-1, keepdim=True)) + self.eps)
if self.use_bias:
return self.gamma * rms_x + self.bias
return self.gamma * rms_xReferences
- [1910.07467] Root Mean Square Layer Normalization
- bzhangGo/rmsnorm: Root Mean Square Layer Normalization