

Last Updated on 2024-08-18 by Clay
Introduction to Cross Entropy
Cross entropy is a very common loss function in Machine Learning, as it is able to quantify the difference between a model’s classification predictions and the actual class labels, particularly in ‘classification tasks’.
In classification problems, the formula for cross entropy is as follows:





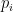




From this formula, we can conclude the following:
- The more accurate the prediction, the smaller the cross-entropy value:
- If the model’s predicted probability for the correct class
- If the model’s predicted probability for the correct class
- If the model’s predicted probability for the correct class
- The role of one-hot encoding:
- In multi-class classification, the correct answer is usually represented in one-hot encoding format (for example, classifying cats and dogs, where a cat is represented by [1, 0] and a dog by [0, 1]). This means only the correct class is 1, and the rest are 0. The model’s predicted probability distribution will only calculate the correct position.
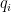


Code Implementation
Here, we consider batch input. In addition to implementing the formula with -np.sum(p * np.log(q)), we also average the loss function. This is done to allow a comparison with PyTorch’s implementation later.
def my_cross_entropy(p, q):
return -np.sum(p * np.log(q)) / len(p)Below is a randomly defined test case. PyTorch accepts logits as input, not probabilities, and internally calculates the probability distribution with softmax. Our implementation, however, defines a softmax function, which converts logits to probabilities before passing them to the custom my_cross_entropy().
import torch
import numpy as np
def my_cross_entropy(p, q):
return -np.sum(p * np.log(q)) / len(p)
def my_softmax(logits):
exp_logits = np.exp(logits)
return exp_logits / np.sum(exp_logits, axis=1, keepdims=True)
# Test case
if __name__ == "__main__":
# Real data (cat, dog, turtle)
real_data = [
[1, 0, 0],
[1, 0, 0],
[0, 0, 1],
]
model_predictions = [
[9.7785, 0.9195, 2.10],
[3.133, -3.05, 1.02],
[0.12, 0.432518, 0.470],
]
# Torch
real_data_indices = np.argmax(real_data, axis=1)
real_data_torch = torch.tensor(real_data_indices)
model_predictions_torch = torch.tensor(model_predictions)
torch_loss = torch.nn.functional.cross_entropy(model_predictions_torch, real_data_torch)
print("Torch Cross Entropy Loss:", torch_loss.item())
# My Cross Entropy
model_predictions_softmax = my_softmax(np.array(model_predictions)) # Apply softmax
my_loss = my_cross_entropy(np.array(real_data), model_predictions_softmax)
print("My Cross Entropy Loss:", my_loss)
Output:
Torch Cross Entropy Loss: 0.36594846844673157
My Cross Entropy Loss: 0.36594851568931036
You can see that our implementation is very consistent with PyTorch.