

Last Updated on 2024-08-18 by Clay
交叉熵介紹
交叉熵是機器學習(Machine Learning) 中非常常見的損失函數,這是因為其交叉熵是一種可以在『分類任務』中,將模型分類預測結果和實際分類標籤之間的差異做出量化。
在分類問題中,交叉熵的公式如下:





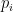




仔細觀察此一公式,我們可以得到以下結論:
- 預測越準確,交叉熵值越小:
- 若是模型對於正確的預測機率
- 若是模型對於正確的預測機率
- 若是模型對於正確的預測機率
- one-hot encoding 的作用:
- 在多類別分類中,我們的標準答案通常是以 one-hot encoding 的格式存在(如今天分類貓和狗,貓就以 [1, 0] 代表、狗就以 [0, 1] 代表)。這意味著只有正確的類別是 1,其餘為 0,模型的預測機率分佈只會計算在正確的位置上
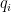


程式實作
在這裡,我們考慮批次輸入的情況,除了 -np.sum(p * np.log(q))複現上述公式外,也平均了損失函數。這是為了等一下與 PyTorch 的實現相比。
def my_cross_entropy(p, q):
return -np.sum(p * np.log(q)) / len(p)以下是一個隨機定義的測試資料,PyTorch 接受的輸入並非機率值,而是模型最後一層輸出的 logits,它會在內部自己做 softmax 來計算機率分佈,而我們的實作則是也自行定義了一個 softmax 的函式,先把 logits 轉換成機率分佈後再輸入自定義的 my_cross_entropy()。
import torch
import numpy as np
def my_cross_entropy(p, q):
return -np.sum(p * np.log(q)) / len(p)
def my_softmax(logits):
exp_logits = np.exp(logits)
return exp_logits / np.sum(exp_logits, axis=1, keepdims=True)
# Test case
if __name__ == "__main__":
# Real data (cat, dog, turtle)
real_data = [
[1, 0, 0],
[1, 0, 0],
[0, 0, 1],
]
model_predictions = [
[9.7785, 0.9195, 2.10],
[3.133, -3.05, 1.02],
[0.12, 0.432518, 0.470],
]
# Torch
real_data_indices = np.argmax(real_data, axis=1)
real_data_torch = torch.tensor(real_data_indices)
model_predictions_torch = torch.tensor(model_predictions)
torch_loss = torch.nn.functional.cross_entropy(model_predictions_torch, real_data_torch)
print("Torch Cross Entropy Loss:", torch_loss.item())
# My Cross Entropy
model_predictions_softmax = my_softmax(np.array(model_predictions)) # Apply softmax
my_loss = my_cross_entropy(np.array(real_data), model_predictions_softmax)
print("My Cross Entropy Loss:", my_loss)
Output:
Torch Cross Entropy Loss: 0.36594846844673157
My Cross Entropy Loss: 0.36594851568931036
可以看到我們的實現與 PyTorch 非常一致。