

Last Updated on 2024-08-18 by Clay
Gaussian Error Linear Unit (GELU) is an activation function used in machine learning. While it resembles the classic ReLU (Rectified Linear Unit), there are some key differences.

ReLU is a piecewise linear function that outputs 0 for inputs less than 0, and outputs the input itself for inputs greater than 0.
ReLU(x) = max(0, x)
GELU was introduced by Dan Hendrycks and Kevin Gimpel in 2016. It combines the input of the neuron with the standard Gaussian cumulative distribution function to form a nonlinear activation function.

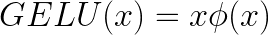
Here, Φ(x) represents the cumulative distribution function (CDF) of a standard normal variable, which can be written as:

![\phi(x)=\frac{1}{2}[1+erf(\frac{x}{\sqrt{2}})]](https://s0.wp.com/latex.php?latex=%5Cphi%28x%29%3D%5Cfrac%7B1%7D%7B2%7D%5B1%2Berf%28%5Cfrac%7Bx%7D%7B%5Csqrt%7B2%7D%7D%29%5D+&bg=ffffff&fg=000&s=4&c=20201002)
erf() is an error function, defined as:


In PyTorch, we can easily observe the behavior of this function by calling torch.erf():
import torch
x = torch.tensor([-2.0, -1.5, -1.0, -0.5, 0, 0.5, 1.0, 1.5, 2.0])
print(torch.erf(y))
# Out: tensor([-0.9953, -0.9661, -0.8427, -0.5205, 0.0000, 0.5205, 0.8427, 0.9661, 0.9953])When the input is negative, the value of the error function is also negative. As the input becomes smaller, the value of the error function decreases (though you can observe that the farther t is from 0, the slower the cumulative integral growth due to
When the input is 0, the output is also 0, as the integral ranges from 0 to 0.
When the input is positive, the value of the error function is positive, and it increases as the input increases, but will not exceed 1.


In PyTorch, GELU can actually be implemented in different approximate ways, such as:

![0.5x(1+tanh[\sqrt{\frac{2}{\pi}}(x+0.044715x^{3})])](https://s0.wp.com/latex.php?latex=0.5x%281%2Btanh%5B%5Csqrt%7B%5Cfrac%7B2%7D%7B%5Cpi%7D%7D%28x%2B0.044715x%5E%7B3%7D%29%5D%29+&bg=ffffff&fg=000&s=4&c=20201002)
Or

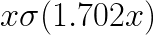
Looking through the official PyTorch documentation and diving into the GELU() implementation, there are both the original and tanh approximation implementations. As of now (2024/03/07), the Sigmoid approximation hasn’t been added to PyTorch, but people have started inquiring about it.
import math
import matplotlib.pyplot as plt
import torch
def GELU(x: torch.Tensor) -> torch.Tensor:
return x * (1 + torch.erf(x / math.sqrt(2))) / 2
def GELU_tanh(x: torch.Tensor) -> torch.Tensor:
return 0.5 * x * (1 + torch.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * pow(x, 3))))
def GELU_sigmoid(x: torch.Tensor) -> torch.Tensor:
return x * torch.sigmoid(1.702 * x)
x = torch.arange(-6, 6, 0.001)
y1 = torch.nn.functional.gelu(x, approximate="tanh")
y2 = torch.tensor(list(map(GELU, x)))
y3 = torch.tensor(list(map(GELU_tanh, x)))
y4 = torch.tensor(list(map(GELU_sigmoid, x)))
plt.plot(x, y1, label="Torch GELU")
plt.plot(x, y2, label="My GELU")
plt.plot(x, y3, label="My GELU_tanh")
plt.plot(x, y4, label="My GELU_sigmoid")
plt.title("GELU")
plt.xlabel("x")
plt.ylabel("y")
plt.legend(loc="upper right")
plt.show()
Output:

print("Original:", max(y1 - y2))
print("Tanh:", max(y1 - y3))
print("Sigmoid:", max(y1 - y4))
Output:
Original: tensor(0.0005) Tanh: tensor(2.3842e-07) Sigmoid: tensor(0.0207)
If we choose the tanh parameter: torch.nn.functional.gelu(x, approximate="tanh"), it will automatically switch to the tanh approximation.
Interestingly, if we limit the range to between -1 and 1, the sigmoid approximation approaches 0, which seems to suggest there’s value in adding it to PyTorch’s native implementation.
In summary, one of the advantages of GELU is that it introduces information even in the negative domain, unlike ReLU which sets negative values to 0. Additionally, GELU is differentiable across the entire input domain, whereas ReLU is not differentiable at zero. This smoothness helps optimize the model more effectively through gradient descent.
In practice, GELU has been widely adopted in architectures like BERT and other Transformers, demonstrating great performance. It can be considered a well-proven activation function.