

Last Updated on 2024-10-16 by Clay
The following are some points in this paper:
- The Decoder-only Transformer is a robust architecture but not the only choice.
- The researchers introduce a triplet-counting task and demonstrates the advantages of Encoder-only Next Token Prediction (ENTP).
- ENTP shows strengths in both length generalization and in-context learning.
- Assuming unlimited computational power, Decoder-only Transformers are not the ideal choice for sequence modeling.
- The researchers suggests a possible future direction: since training ENTP requires more resources compared to Decoder-only Transformers, a more practical approach would be a first train a decoder, then attempt to migrate it to an ENTP architecture.
What Is Encoder Next Token Prediction (ENTP)
Initially, I was confused about using an Encoder for Next Token Prediction (NTP) because wouldn’t it essentially become a Decoder? However, after reading the paper, I realized that the difference between Encoder and Decoder actually lies in the implementation of their Attention Mechanism.
After all, Decoder uses Causal Attention.
Simply put, in the Decoder’s attention mechanism, we create an upper triangular matrix mask the ensure that when tokens interact and compute with each other, they can not see the previously tokens and can only see the left-side tokens. This simulates the scenario during decoding where “only the already existing token are usable.” This is the known as “Causal Attention“.
On the other hand, the Encoder doesn’t use this kind of mask. The Encoder employs bidirectional attention, allowing each token to see all the information in the sequence during interactions and computations.
The researchers point out that Causal Attention is actually an artificial construct and not necessarily essential or advantageous. Of course, from my perspective as a poor-resource researcher, this is certainly necessary to save training resources.

As shown in the figure, in the Decoder-only mode, each input


The changing result is: we can no longer input a single piece of data and perform next-token prediction for all inputs simultaneously. Instead, we must treat each token of the input as a separate data for training.
Let me visualize what I mean.
Decoder-only training mode: {x1, x2, x3… x_n} is a single piece of training data, and the model is trained simultaneously for the prediction tasks from x2 to x_n.
Encoder-only training mode:
1. {x1} predicting x2 is one piece of training data.
2. {x1, x2} predicting x3 is one piece of training data … n-1. {x1, x2, x3, …, x_n-1} predicting x_n is one piece of training data.
In other words, the advantage of parallelized training is lost. We need to spend more time and GPU resources to train our auto-regressive model.
Additionally, the Encoder model cannot use the KV Cache to store previously computed parts. This is because the computation results for each step will change with the addition of new tokens, unlike in the Decoder where previous computations remain unchanged when new tokens are added. Therefore, the KV Cache cannot be used.
Research Approach
The researchers’ approach is to propose an auto-regressive task and verify whether an Encoder can complete it on a small model, whereas a Decoder cannot.
They attempted to fine-tune GPT-4o and Llama3-8B and challenged them with the defined Triplet-Counting task.

The Triplet-Counting task is a problem of counting specific triplets in a sequence, where the core is to check modulo operations and count whether the numbers in the sequence meet certain conditions.
Simply put, the task is to find all pairs

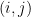




Time Complexity
For each $late x_{i}$ and $late x_{j}$, you need to check all possible pairs

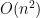
Space Complexity
There are two intuitive algorithms:
- One that computes in
- Another that uses




In the Triplet-Counting task, the difference between Encoder-only Transformers and Decoder-only Transformers is quite significant, as the encoder can recompute attention for each token, which makes it better suited for handling complex computations and understanding the overall sequence.

Of course, one might imagine that this task was deliberately designed to target the weaknesses of Decoder-only Transformers, but in reality, the research team conducted tests on different tasks: length generalization and in-context learning.

Section 6.3 even includes a task from OpenWebText, though personally, I am less confident about the performance regarding perplexity, so I won’t take that into account.
Conclusion
While reading halfway through, I had a feeling that if the Encoder performs better in the Next Token Prediction task without using the Causal Attention mask and is only limited by training efficiency, then perhaps one could first model using Causal Modeling, and then fine-tune using the Encoder’s attention mechanism.
When I reached the conclusion, I saw that the research team indeed explained it this way. Now, here are my personal thoughts—of course, this is by no means a universal truth:
Once I realized that KV Cache could not be used, I stopped having high expectations for the inference speed of the Encoder.
My personal takeaway is that using an Encoder as an LLM is a beautiful ideal, but the reality is that modern hardware performance is not sufficient to make the extra overhead of using the Encoder for next-token decoding negligible. Therefore, researchers and companies will likely continue improving the Decoder-only Transformer architecture.
Perhaps what we need is not to return to building LLMs based on the Encoder architecture, but rather to add more information to the Decoder? Or design an Encoder architecture that can utilize caching mechanisms (not necessarily KV Cache).
The study of neural networks by humans is far from over.