

Last Updated on 2024-10-16 by Clay
以下是這篇論文的一些重點摘要:
- Decoder-only transformer 是個好架構、但並非唯一選擇
- 研究中介紹了 triplet-counting 任務,並展示 Encoder-only Next Token Prediction (ENTP) 的優勢
- ENTP 對於長度泛化和 in-context learning 都有優勢
- 假設運算能力沒有限制,Decoder-only Transformer 並非理想的序列建模
- 研究者提出未來的可能發展:由於訓練上 ENTP 所花費的資源會比 Decoder-only Transformer 來得更多,比較實際的作法應是先訓練 decoder、再嘗試將其遷移到 ENTP 架構上
何為 Encoder Next Token Prediction (ENTP)
一開始我疑惑的點在於把 Encoder 拿去做次詞預測(Next Token Prediction),不就成了 Decoder 了嗎?不過看了論文內容後,發現他們定義的 Encoder 和 Decoder 之間的差異,其實是指兩者的注意力機制實現不同,畢竟 Decoder 使用了 Causal Attention。
展開來說,在 Decoder 的注意力機制中,我們會建立一個上三角矩陣的遮罩(Mask),用以讓每個 Token 在彼此做交互計算時,沒辦法看到自己後方的 Token,只能看到自己前方的 Token,以此來實現真正解碼時『只能看到已經存在的 Token』這樣的情境。而這就被稱為 Causal Attention。
而在 Encoder 中是沒有這樣的遮罩的。因為 Encoder 是雙向的注意力機制,能夠讓每個 Token 在進行交互計算時看到序列中所有的資訊。
研究者提到,這種 Causal Attention 其實是人為引入的,並不一定真的有必要、或是有其優勢。當然,以我這種低資源的研究者的角度來說,這在節省訓練資源肯定是必要的。

可以看到圖中在 Decoder-only 模式時,其每個輸入 x 只能看到過去存在的 x;而在 Encoder-only 時,則可以瀏覽所有的 x 輸入資訊。
這樣做所造成的結果是:訓練時,我們再也不能把一筆資料輸入後,同時對所有的輸入做次詞預測、而是必須在每個輸入的節點都當作是一筆資料去進行訓練。
視覺化一下我想表達的意思。
Decoder-only 訓練模式:
{x1, x2, x3… x_n} 這是一筆訓練資料,同時訓練了模型從 x2 ~ x_n 的預測任務。
Encoder-only 訓練模式:
1. {x1} 預測 x2 是一筆訓練資料
2. {x1, x2} 預測 x3 是一筆訓練資料
.
.
.
n-1. {x1, x2, x3, …, x_n-1} 預測 x_n 是一筆訓練資料
換言之平行化訓練的優勢沒了,我們需要花上更多的時間和 GPU 去訓練我們的自迴歸模型(Auto-regressive model)。
另外,Encoder 模型沒辦法使用 KV Cache 儲存原先計算過的部份,這是因為每一次的計算結果不像 Decoder 那樣不會因為後面加入 New Token 而變動,而是會隨著 New Token 的增加而改變先前的計算狀態,所以沒辦法使用 KV Cache。
研究方式
而研究者的研究方式是,提出一個自迴歸的任務,並驗證是否可以在小模型上 Encoder 能夠完成、而 Decoder 則無法完成。
他們嘗試微調 GPT-4o 和 Llama3-8B,並挑戰定義好的 Triplet Counting 任務。

Triplet Counting 任務是一個計算序列中特定三元組(triplet)的數量問題,這個問題的核心是對模運算進行檢查,並且依據序列中的數字對是否滿足條件進行計數。
簡單來說,任務是需要找到序列中所有組合的數對

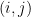




時間複雜度
對於每個 $late x_{i}$ 和 $late x_{j}$ 進行檢查,需要遍歷所有可能的數對

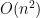
空間複雜度
有兩個很直覺的演算法:
- 使用
- 使用

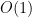



在這個 Triplet-Counting 的任務上,Encoder-only Transformer 和 Decoder-only Transformer 的差距非常明顯;因為編碼器可以重新計算每一個 Token 的注意力,更能應付複雜的計算和對序列整體的理解力。

當然,我們可能會想像說這是故意設計出來針對 decoder-only Transformer 的任務,但實際上,研究團隊確實做了不同的任務測試:長度泛化與 in-context learning。

6.3 小節甚至還放了一個 OpenWebText 的任務,不過我個人對於困惑度的表現比較沒有把握,所以就不列入參考。
結論
我在看到一半時,就有感覺說如果 Encoder 不用 Causal Attention 遮罩在 Next Token Prediction 任務表現得更好,而僅僅只是卡在訓練效率上,那先使用 Causal Modeling 的方式建模、再轉為使用 Encoder 的注意力機制進行微調。
看到結論,發現研究者團隊還真的這樣說明了。那麼以下來說說我個人的看法,當然這絕對不是真理:
一旦想通了終究還是無法使用 KV Cache 後,對於 Encoder 的推理速度就沒抱持著太大期望了。
我自己的感想是使用 Encoder 來作為 LLM 去應用是一個很美好的理想,然而現實情況是現代的硬體性能並不足以讓 Encoder 做次詞解碼的額外開銷被視若無誤,所以各個研究者與企業應還是會繼續走在改進 Decoder-only Transformer 的架構上。
或許我們需要的不是重新回到 Encoder 的架構去搭建 LLM,而是在 Decoder 中額外添加資訊?或是設計一套可以應用 Cache 機制的 Encoder 架構(不一定是 KV Cache)。
人類對於類神經網路的研究,還遠遠沒走到盡頭吧。