

Last Updated on 2024-11-11 by Clay
Introduction
Recently, I’ve been trying to organize the papers on accelerated reasoning techniques I’ve read over the past year into notes. During this process, I came across Bayesian optimization techniques that utilize Bayes’ theorem, so I decided to write a note to record the essence of Bayes’ theorem.
In simple terms, Bayes’ theorem is a frequently encountered theorem in probability theory that describes the probability of a random event occurring under specific conditions.
What is Bayes’ Theorem?

Suppose we have random events A and B, and

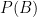


A practical calculation can make this clear:
Now we know:








In Bayes’ theorem, there are some fixed terms:

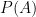
Real-World Example
There’s an interesting example on Wiki that I think illustrates the power of Bayes’ theorem very well.
Consider a scenario where a drug user undergoes drug testing. The probability of a drug user testing positive (+) is 99%. For non-drug users, the probability of testing negative (-) is 99%:
- Event
- Event
- Event







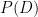






Intuitively, we might think this testing method is very accurate, but what does the ‘real situation’ look like?
Assuming there are 1,000 testers in total, actually 5 people are drug users, and 995 people are not drug users.
So based on the actual proportion of drug users, we can calculate







In other words, under these conditions, the probability of a positive result in a single test is 1.49%, which is higher than the probability of drawing a specific SSR card.
What about false positives? That is, how many people are we actually wronging? Let’s use Bayes’ theorem to calculate the probability that someone is truly a drug user when they test positive.


Only about one-third! That is, when we detect someone as a drug user, there is a high probability that we have wronged them.
Through Bayes’ theorem, the unreliability of this test result becomes very apparent.
Conclusion
In machine learning tasks, one common application of Bayes’ theorem is the Bayesian classifier, which is a task I’m relatively familiar with.
In simple terms, during the training phase of a naive Bayesian classifier, the main task is to use the training data to estimate the prior probabilities of each class and the conditional probabilities of each feature given a class. Therefore, we have to perform some processing, such as ensuring features are discrete, or at least fit a Gaussian distribution so we can apply formulas to calculate conditional probabilities, and handling unprocessed features when facing test data (real-world data) in the future, etc.
However, after we complete these conditional probabilities for different classes, we can use these probabilities to determine the class with the highest probability for new data.
Later on, I’m less familiar with tasks like Bayesian optimization, and I hope to find time to learn about it soon.