

Last Updated on 2024-11-07 by Clay
前言
最近在嘗試整理這一年來所閱讀的加速推理技巧論文成筆記,過程中看到了用到了貝氏的貝氏優化技巧,遂決定也寫一篇筆記記錄貝氏定理的精神。
簡單來說,貝氏定理(Bayes’ Theorem)是機率論中的經常會看到的定理,描述在特定條件下一隨機事件的發生機率。
貝氏定理是什麼?

假設我們有隨機事件 A 和 B,並且

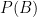


實際計算一次也能明白:
現在我們已經知道:








而在貝氏定理中,有一些固定的名稱:

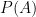
實際案例
在 Wiki 上舉例了一個很有趣的例子,我覺得很好地表示了貝氏定理的威力。
有一個吸毒者接受吸毒檢測的情境,吸毒者每次檢測呈陽性(+)的機率為99%。而不吸毒者每次檢測呈陰性(-)的機率為99%:







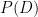






直覺上我們會覺得這個檢測方式十分準確,但是『真實情況』看起來又如何呢?
假設整體檢測者共有 1,000 人,實際上有 5 個人吸毒,995 個人不吸毒。
所以實際上我們基於真實吸毒的比例,我們可以計算得出







換句話說,現在我們在這個條件下進行檢測,一次檢測的結果為陽性的機率就是 1.49%,比抽特定 SSR 卡的機率還高。
那麼,偽陽性呢?就是我們實際上到底會冤枉多少人呢?我們來透過貝氏定理實際計算一下某人檢測陽性時,『某人真的是吸毒者的機率』。


大概只有三分之一!也就是說,當我們檢測出某人是吸毒者時,實際上大機率是冤枉了他。
透過貝氏定理來看,這個檢測結果的不可靠性就非常明顯。
結語
在機器學習任務中,貝氏定理挺常見的一種應用就是貝氏分類器(Bayesian Classifier),這也是我相對熟悉的任務。
簡單來說,樸素貝氏分類器在訓練階段的主要任務是利用訓練資料來估計各個類別的先驗機率(prior probabilities)以及在給定類別下各個特徵(features)的條件機率(conditional probabilities);所以,我們不得不做一些處理,比方說特徵可能得是非連續的、或是至少符合高斯分佈讓我們可以套用公式計算條件機率、以及在未來面對測試資料(真實世界)時未處理過的特徵…… 等等。
不過在我們完成這些不同類別的條件機率後,我們就可以使用這些機率來判斷新資料最高機率的分類類別了。
之後,我相對不熟悉的任務是貝氏優化,希望能找個時間盡快學習一下呢。