

Last Updated on 2021-07-01 by Clay
LSTM (Long Short-Term Memory),中文翻譯做『長短期記憶』,是一種循環神經網路 (RNN)。其論文發表於 1997 年,是在自然語言處理當中非常重要、並且好用的模型層。
由於我經常會使用 LSTM 來處理我的任務,故一直尋思著要整理一篇筆記。這樣一來,以後若是有碰到 LSTM 相關的問題,我都可以回頭來翻閱我的筆記,省去了在網路上四處瀏覽的時間。
為了我自己的查看方便,這篇筆記會分成兩部份。前半是紀錄 LSTM 原理的部份、後半則是專門紀錄在 PyTorch 當中 LSTM 的使用格式。
LSTM 的原理
由於這篇文章是我用來紀錄學習過程的文章,故有些圖片與原理的解說是參考他人文章。以下的內要參考網頁的連結會附在最底下的 References 區塊,示例圖片有侵權,麻煩告知我,我會馬上撤換 —— 我對於這些前輩大神們製作的圖片只有尊敬的意思,非常感謝他們製作了淺顯易懂的圖片幫助我學習。
LSTM 可以視為 RNN 的複雜版本,基本上最重要的是就是在不同時序的神經元間會有參數傳遞。以下是個 RNN 的架構圖,可以看到除了向前傳播的 h 值以外,神經元彼此之間按照時序傳遞資訊。
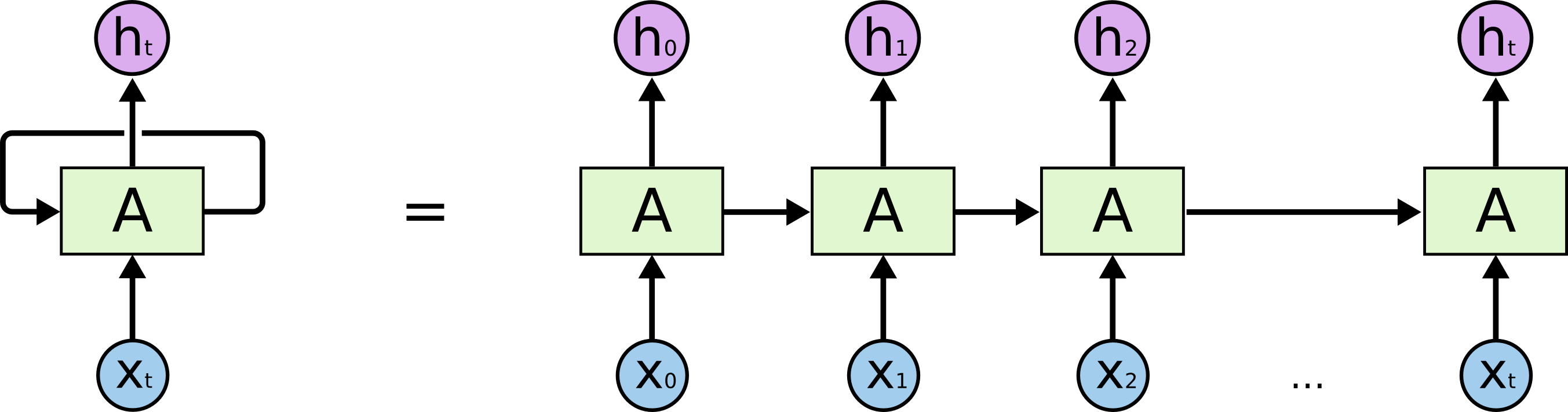
然而 LSTM 單個神經元的架構明顯複雜多了:


以下來看看神經元的資料處理過程。基本上慢慢按照公式思考就會比較明白。

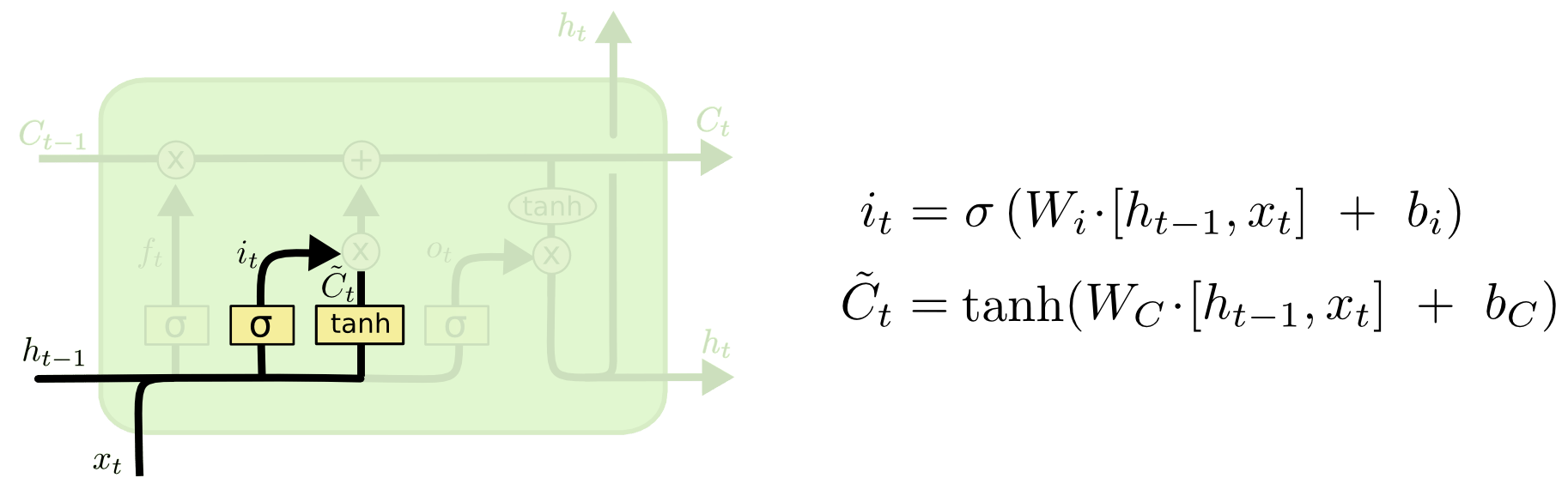

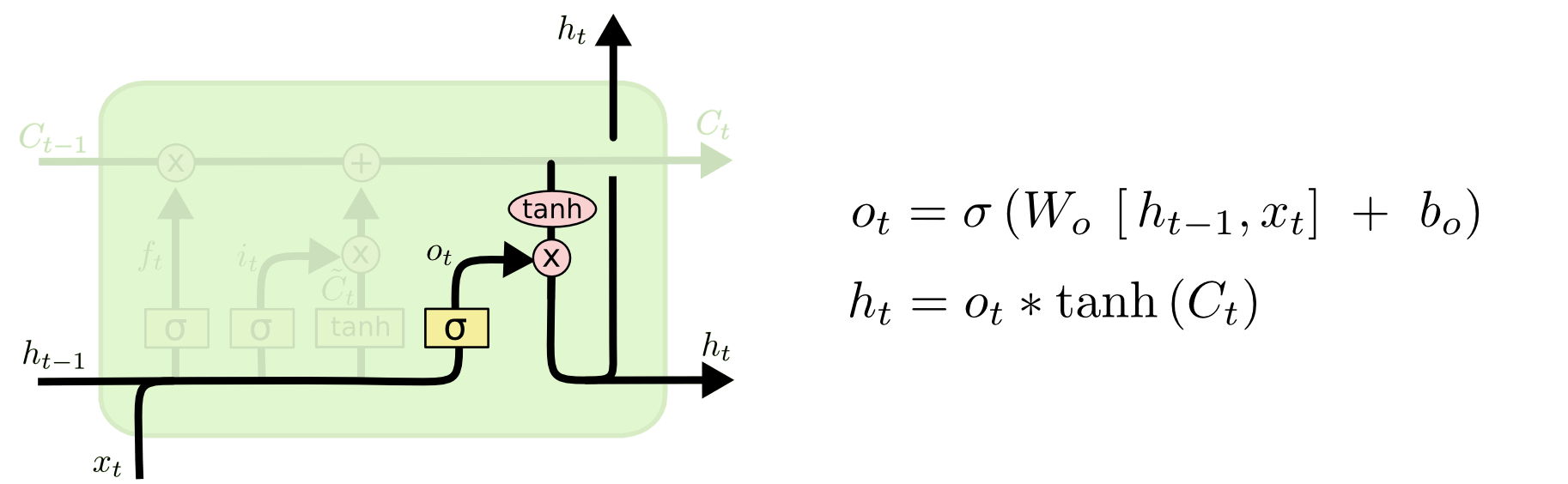
PyTorch 中 LSTM 使用方法
LSTM 的參數:
- input_size: 輸入 x 的特徵數量
- hidden_size: 隱藏層 h 的特徵數量
- num_layers: LSTM 的循環層數 (Default=1)
- bias: 若為 False,則 bias 初始化為 0 (Default=True)
- batch_first: 若為 True,則輸入維度為 (batch_size, seq_len, feature)
- dropout: 若不為 0,則在每一層 LSTM 後都會接著 dropout (Default=0)
- bidirectional: 若為 True,則為雙向 LSTM (Default=False)
再來,我想要紀錄起資料在 LSTM 當中的變化。
首先,我們假設輸入的維度為 (batch_size, seq_len, input_size) —— 當然,這是 batch_first=True 的情況。
PyTorch 中定義的模型如下:
# coding: utf-8 import torch.nn as nn # LSTM class LSTM(nn.Module): def __init__(self, input_size, hidden_size, num_layers, bidirectional): super(LSTM, self).__init__() self.lstm = nn.LSTM( input_size=input_size, hidden_size=hidden_size, num_layers=num_layers, bidirectional=bidirectional, ) self.fc = nn.Linear(hidden_size, 1) self.sigmoid = nn.Sigmoid() def forward(self, inputs): out, (h_n, c_n) = self.lstm(inputs, None) outputs = self.fc(h_n.squeeze(0)) return self.sigmoid(outputs)
我們可以看到,這是一個 LSTM 的分類器,重要的是我們的三個 Output: “out”、”h_n”、”c_n”。以下我們分別來看看。
out (batch_first=True)
out: (batch_size, seq_len, hudden_size * num_directions)
out 是三維的 Tensor,第一維為 Batch Size,第二維為序列長度,第三維為『隱藏層大小 x num_directions』。隱藏層大小就是 hidden_size 設定的大小、num_directions 就是雙向 LSTM 為 2、單向為 1。
h_n
h_n: (num_layers * num_directions, batch_size, hidden_size)
num_layers 的意思為 LSTM 的隱藏層有幾層,除此之外都與上方 “out” 的解釋相仿。
c_n
c_n: (num_layers * num_directions, batch_size, hidden_size)
c_n 與 h_n 的構造相仿,唯一的差別在於 h_n 是 h 的輸出、c_n 則是 c 的輸出,可以參考上方的結構圖。
Bi-LSTM 的輸出
Bi-LSTM 比較不同,由於最後的輸出為『雙向』的,所以我們會得到一個順時序的輸出以及逆時序的輸出,這時候若是直接將其合併用以進行分類,通常效果會不太好。
我們要做的就是將逆時序的輸出再反過來,再與順時序的輸出合併。
順帶一提,在 PyTorch 當中直接設定 “Bidirectional=True” 是有點小問題的。其中最大的問題是無法以固定的 Seed 去固定其輸出結果。這在實驗模型中是危險的——因為你無法重複自己所做的實驗。
References
- https://colah.github.io/posts/2015-08-Understanding-LSTMs/
- https://adventuresinmachinelearning.com/keras-lstm-tutorial/
- https://medium.com/mlreview/understanding-lstm-and-its-diagrams-37e2f46f1714
- https://pytorch.org/tutorials/beginner/nlp/sequence_models_tutorial.html
- https://pytorch.org/tutorials/intermediate/char_rnn_classification_tutorial.html