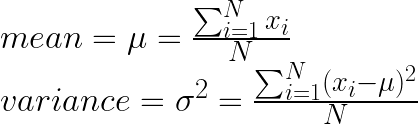[PyTorch] 使用 2.0+ 的 SDPA 提昇 Transformer 自注意力機制計算速度

Last Updated on 2024-03-25 by Clay
SDPA 介紹
縮放點積注意力(Scaled Dot-Product Attention, SDPA)對於熟悉 Transformer 自注意力架構(Self-Attention)的人來說,恐怕馬上腦海中瞬間就閃過了:
 Read More »[PyTorch] 使用 2.0+ 的 SDPA 提昇 Transformer 自注意力機制計算速度
Read More »[PyTorch] 使用 2.0+ 的 SDPA 提昇 Transformer 自注意力機制計算速度