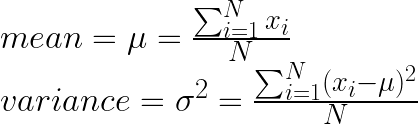[PyTorch] 使用 2.0+ 的 SDPA 提昇 Transformer 自注意力機制計算速度

Last Updated on 2024-03-25 by Clay
SDPA 介紹
縮放點積注意力(Scaled Dot-Product Attention, SDPA)對於熟悉 Transformer 自注意力架構(Self-Attention)的人來說,恐怕馬上腦海中瞬間就閃過了:


Last Updated on 2024-03-25 by Clay
縮放點積注意力(Scaled Dot-Product Attention, SDPA)對於熟悉 Transformer 自注意力架構(Self-Attention)的人來說,恐怕馬上腦海中瞬間就閃過了:

Last Updated on 2024-03-18 by Clay
(備註:由於本篇文章自我個人 Hackmd 導入,所以有些符號跟 WordPress 顯示不對位,還請閱讀者多多包涵,Sorry~)
RoPE 是一種通過絕對位置編碼的方式,引入相對位置的資訊給自注意力機制(Self-Attention Mechanism)的位置嵌入。
Read More »[Machine Learning] 旋轉位置嵌入 (Rotary Position Embedding, RoPE)筆記
Last Updated on 2024-08-18 by Clay
RMSNorm 是對於 LayerNorm 的一種改進,經常用於 Transformer 自注意力機制,旨在減輕梯度消失和梯度爆炸的問題,從而幫助模型更快收斂並提高性能。
Read More »[Machine Learning] RMSNorm 筆記Last Updated on 2024-08-18 by Clay
高斯誤差線性單元(Gaussian Error Linear Unit, GELU)是一種機器學習中會使用到的激活函數。跟經典的 ReLU(Rectified Linear Unit)雖然相像卻有些地方不盡相同。
Read More »[Machine Learning] GELU 激活函數筆記Last Updated on 2024-03-08 by Clay
以前我的指導教授常常告訴我,不要僅僅只是使用別人的套件,一定要自己寫過才會有感覺。當時我沒有太多的時間去實現各種我感興趣的技術,光是拼出論文就已經竭盡全力了。但是直到現在仍時常回想教授的諄諄教誨,忍不住開始動手實現 BERT 這一經典架構的 encoder-only transformer 模型。
Read More »[PyTorch] BERT 架構實現筆記Last Updated on 2024-03-08 by Clay
LayerNorm 的工作原理如下: