

Last Updated on 2025-05-05 by Clay
介紹
Proximal Policy Optimization(PPO)是一種在強化學習(Reinforcement Learning, RL)領域非常知名且效果卓越的一種策略梯度(Policy Gradient)演算法,由 OpenAI 在 2017 年提出,旨在解決傳統策略梯度方法在訓練穩定性上的一些問題。
閱讀全文: Proximal Policy Optimization(PPO)筆記策略梯度
而所謂的策略梯度與價值基礎(Value-based,如 Q-Learning 和 DQN)不同,策略本身並不是一個價值函數,而通常由另外一個神經網路表示,通常記作





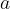


而策略梯度的目標就是找到一組最佳的參數



![J(\theta)=\mathbb{E}_{\tau\sim\pi_{\theta}}[R(\tau)]](https://s0.wp.com/latex.php?latex=J%28%5Ctheta%29%3D%5Cmathbb%7BE%7D_%7B%5Ctau%5Csim%5Cpi_%7B%5Ctheta%7D%7D%5BR%28%5Ctau%29%5D+&bg=ffffff&fg=000&s=4&c=20201002)
在這裡:
- $latex \mathbb{E}{r\sim\pi{\theta}}[…] &s=1$ 表示對所有遵循策略
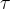






至於實際上是怎麼讓我們想要優化的模型學習、調整參數呢?那就是使用梯度上升(Gradient Ascent)。我們需要計算根據目標函數






其中


PPO 核心概念
傳統的策略梯度方法(例如 REINFORCE 或 A2C 的基本形式)直接計算策略梯度並更新策略網路的參數,目標是最大化期望的累積獎勵;然而,這類方法對於學習率非常敏感,如果學習率太大,策略可能會劇烈變動,導致性能崩潰;反之若是太小,則會是訓練非常緩慢。
Trust Region Policy Optimization (TRPO) 試圖解決這個問題,它透過限制新舊策略之間的 KL 散度(KL Divergence)來確保每次更新都在一個信任區域內進行,避免策略劇烈變動,但是因其計算複雜,實作較為困難。
PPO 是想要實現 TRPO 的穩定性,但使用更簡單的方法。它不像是 TRPO 那樣直接強制 KL 散度約束,而是透過修改目標函數來間接限制策略更新的幅度。
PPO-Clip
這是最常見的 PPO 型態,其核心就在於特殊的剪裁目標函數。
它首先計算了新策略










接著,PPO-Clip 計算一個優勢函數(Advantage Function)


如果
PPO-Clip 的目標函數定義如下:



![L^{CLIP}(\theta)=\mathbb{E}\left[ min\left( r_t(\theta)\hat A_t,clip(r_t(\theta),1-\epsilon,1+\epsilon)\hat A \right) \right]](https://s0.wp.com/latex.php?latex=L%5E%7BCLIP%7D%28%5Ctheta%29%3D%5Cmathbb%7BE%7D%5Cleft%5B+min%5Cleft%28+r_t%28%5Ctheta%29%5Chat+A_t%2Cclip%28r_t%28%5Ctheta%29%2C1-%5Cepsilon%2C1%2B%5Cepsilon%29%5Chat+A+%5Cright%29+%5Cright%5D+&bg=ffffff&fg=000&s=4&c=20201002)
- 而




![\left[ 1-\epsilon,1+\epsilon \right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B+1-%5Cepsilon%2C1%2B%5Cepsilon+%5Cright%5D+&bg=ffffff&fg=000&s=1&c=20201002)













以結論來說,透過一個簡單的剪裁動作,約束了模型的策略更新幅度,提昇了訓練的穩定性。
PPO 的實現(Actor-Critic 架構)

PPO 通常與 Actor-Critic 架構結合使用。簡單來說,Actor(策略網路)負責根據當前狀態


而 Critic(價值網路)則負責估計狀態的價值



- 做出預測:當 Agent 處於某個狀態
- 觀察實際發生的結果:Agent 根據 Actor 的策略,在
- 此時 Critic 擁有了更即時的資訊(立即獎勵






其中
- 計算預測誤差:Critic 比較自己最初的預測以及更可靠的 TD Target






接著 Critic 網路就可以通過像是均方誤差這類損失函數進行更新了。
順帶一提,Actor 和 Critic 通常會共享一部分的網路層,以提高學習效率。
總結
總結來說,PPO 是一種透過巧妙設計目標函數(特別是 PPO-Clip 中的裁剪機制)來限制策略更新幅度,從而實現穩定高效訓練的強化學習演算法。它結合了 Actor-Critic 架構,在易用性、穩定性和性能之間取得了很好的平衡,使其成為目前應用最廣泛的強化學習算法之一。
相較於 TRPO 難以實作與運算開銷較大,PPO 在實作簡單性與穩定性之間提供了一個極佳的折衷,因此廣泛應用在 Atari 遊戲、連續控制(MuJoCo)甚至 RLHF 訓練大型語言模型中,成為目前最具代表性的策略梯度方法之一。
References
- Multiple-UAV Reinforcement Learning Algorithm Based on Improved PPO in Ray Framework
- [1707.06347] Proximal Policy Optimization Algorithms