

Last Updated on 2024-08-19 by Clay
The working principle of LayerNorm is as follows:
- Calculate mean and variance

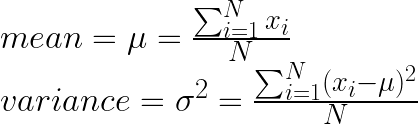
- Normalize using the mean and variance

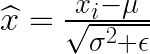
ϵ is a small number added to avoid division by zero.
- Linear transformation
Finally, a learnable scale parameter γ and shift parameter β (both learned through training, initialized as γ = 1 and β = 0) are used to perform a linear transformation on each input element.

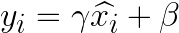
The reason for this is to allow the model to initially not alter the normalized output, gradually learning the best adjustment parameters through training.
Here’s a simple PyTorch implementation:
import torch
class MyLayerNorm(torch.nn.Module):
def __init__(self, normalized_shape, eps: float = 1e-5) -> None:
super().__init__()
self.eps = eps
self.gamma = torch.nn.Parameter(torch.ones(normalized_shape))
self.beta = torch.nn.Parameter(torch.zeros(normalized_shape))
def forward(self, x: torch.Tensor) -> torch.Tensor:
mean = x.mean(dim=(-1,), keepdim=True)
std = x.std(dim=(-1,), keepdim=True, unbiased=False)
x_normalized = (x - mean) / (std + self.eps)
return self.gamma * x_normalized + self.beta
# Inputs
batch_size = 4
dim = 20
x = torch.rand(batch_size, dim)
# My LayerNorm
my_layer_norm = MyLayerNorm(normalized_shape=20)
x_normalized = my_layer_norm(x)
# Official LayerNorm
official_layer_norm = torch.nn.LayerNorm(dim)
x_normalized_official = official_layer_norm(x)
print("Diff:", x_normalized - x_normalized_official)
print("Max:", torch.max(x_normalized - x_normalized_official))
Output:
Diff: tensor([[-4.6015e-05, 7.2122e-06, 1.6093e-05, -2.7657e-05, 2.4617e-05,
5.2810e-05, -2.3901e-05, -3.0756e-05, 4.5896e-06, -3.6478e-05,
4.6492e-05, 5.4479e-05, 9.0301e-06, -7.4059e-06, -2.9624e-05,
-3.9577e-05, -3.8147e-05, 1.8299e-05, 2.9027e-05, 1.1176e-05],
[ 1.2219e-05, -1.1958e-06, 1.3947e-05, -1.8477e-05, 3.0756e-05,
-3.0279e-05, -3.4571e-05, -3.5524e-05, 7.5400e-06, 2.5868e-05,
-3.3379e-05, 2.2292e-05, 2.7537e-05, -9.3132e-07, -1.7941e-05,
2.4915e-05, -1.5795e-05, -9.8646e-06, 1.9595e-06, 3.0756e-05],
[ 2.5034e-05, -5.2810e-05, 2.6703e-05, 4.8757e-05, 2.6405e-05,
-8.8215e-06, 2.7299e-05, -1.7226e-05, 1.4827e-06, 2.6643e-05,
9.3132e-09, -5.6386e-05, 2.2948e-05, -1.4678e-06, 9.4771e-06,
-3.9697e-05, -3.8743e-05, 3.2425e-05, -1.5974e-05, -2.0623e-05],
[-5.6624e-05, -1.9819e-05, 5.9962e-05, 3.7998e-06, 7.2598e-05,
-7.7128e-05, 1.0788e-05, 4.2319e-05, 2.0355e-05, 1.6630e-05,
7.0691e-05, -3.1710e-05, -5.1022e-05, -4.5538e-05, -1.3143e-05,
2.3484e-05, -1.4067e-05, -1.2577e-05, -3.9399e-05, 3.8266e-05]],
grad_fn=<SubBackward0>)
Max: tensor(7.2598e-05, grad_fn=<MaxBackward1>)
In this example, we calculate the standard deviation (std) instead of variance to make it closer to the original PyTorch implementation. Standard deviation is the square root of the variance.